20 hyödyllistä egrep-komentoesimerkkiä Linuxissa
Lyhyesti: Tässä oppaassa käsittelemme joitain käytännön esimerkkejä egrep-komennosta. Tämän oppaan noudattamisen jälkeen käyttäjät voivat suorittaa tekstihaun tehokkaammin Linuxissa.
Oletko koskaan ollut turhautunut, koska et löydä tarvittavia tietoja lokeista? Tarvittavien tietojen poimiminen suuresta tietojoukosta on monimutkainen ja aikaa vievä tehtävä.
Asiat muuttuvat todella haastaviksi, jos käyttöjärjestelmä ei tarjoa oikeita työkaluja ja Linux tulee pelastamaan sinut. Linux tarjoaa erilaisia tekstinsuodatusapuohjelmia, kuten sed, cut jne.
Egrep on kuitenkin yksi tehokkaimmista ja yleisimmin käytetyistä apuohjelmista tekstinkäsittelyyn Linuxissa, ja aiomme keskustella joistakin esimerkeistä egrep-komennosta.
Egrep-komennon Linuxissa tunnistaa grep-komennon perhe, jota käytetään tiedostojen tietyn mallin etsimiseen ja vastaamiseen. Se toimii samalla tavalla kuin grep -E (grep Extended regex), mutta se etsii useimmiten tietystä tiedostosta tai jopa rivistä riville tai tulostaa rivin tietyssä tiedostossa.
Egrep-komennon syntaksi on seuraava:
$ egrep [OPTIONS] PATTERNS [FILES]
Luodaan esimerkkitekstitiedosto, jossa on seuraava sisältö esimerkkiä varten:
$ cat sample.txt

Täällä näemme, että tekstitiedosto on valmis. Keskustellaan nyt muutamasta yleisestä esimerkistä, joita voidaan käyttää päivittäin.
Aloitetaan yksinkertaisella mallinsovitusesimerkillä, jossa voimme käyttää alla olevaa komentoa etsiäksemme merkkijonoa professional sample.txt-tiedostosta:
$ egrep professionals sample.txt

Tässä näemme, että komento tulostaa rivin, joka sisältää määritetyn kuvion.
Voimme tehdä lähdöstä informatiivisemman korostamalla vastaavan kuvion. Tämän saavuttamiseksi voimme käyttää egrep-komennon --color-vaihtoehtoa. Esimerkiksi alla oleva komento korostaa tekstin ammattilaiset punaisella värillä:
$ egrep --color=auto professionals sample.txt

Tässä voimme nähdä, että sama tulos on informatiivisempi kuin edellinen. Lisäksi voimme helposti tunnistaa, että sana ammattilaiset toistetaan kaksi kertaa.
Useimmissa Linux-järjestelmissä yllä oleva asetus on oletusarvoisesti käytössä seuraavalla aliaksella:
$ alias egrep='egrep –color=auto'
Egrep-komento hyväksyy useita tiedostoja argumenttina, mikä antaa meille mahdollisuuden etsiä tiettyä kuviota useista tiedostoista. Ymmärretään tämä esimerkin avulla.
Luo ensin kopio sample.txt-tiedostosta:
$ cp sample.txt sample-copy.txt
Etsi nyt kaava professionals molemmista tiedostoista:
$ egrep professionals sample.txt sample-copy.txt

Yllä olevassa esimerkissä voimme nähdä tiedostonimen tulosteessa, joka edustaa vastaavaa riviä kyseisestä tiedostosta.
Joskus meidän on vain selvitettävä, onko kuvio tiedostossa vai ei. Jos kyllä, kuinka monella rivillä se on? Tällaisissa tapauksissa voimme käyttää komennon -c-vaihtoehtoa.
Esimerkiksi alla oleva komento näyttää tulosteena 1, koska sana ammattilaiset on vain yhdellä rivillä.
$ egrep -c professionals sample.txt 1
Edellisessä esimerkissä näimme, että vaihtoehto -c ei laske kuvion esiintymisten määrää. Esimerkiksi sana professionals esiintyy kahdesti samalla rivillä, mutta vaihtoehto -c käsittelee sitä vain yhtenä osumana.
Tällaisissa tapauksissa voimme käyttää komennon vaihtoehtoa -o tulostaaksemme vain vastaavan kuvion. Esimerkiksi alla oleva komento näyttää sanan ammattilaiset kahdella erillisellä rivillä:
$ egrep -o professionals sample.txt
Lasketaan nyt rivit wc-komennolla:
$ egrep -o professionals sample.txt | wc -l

Yllä olevassa esimerkissä olemme käyttäneet egrep- ja wc-komentojen yhdistelmää tietyn kuvion esiintymisten määrän laskemiseen.
Oletuksena egrep suorittaa kuvioiden sovituksen isot ja pienet kirjaimet huomioiden. Se tarkoittaa sanoja – meitä, Meitä, MEitä ja MEIDÄT kohdellaan eri sanoina. Voimme kuitenkin pakottaa haun, jossa kirjainkoolla ei ole merkitystä, käyttämällä -i-vaihtoehtoa.
Esimerkiksi alla olevassa komentomallissa osuma onnistuu tekstille we ja We:
$ egrep -i we sample.txt

Edellisessä esimerkissä näimme, että egrep-komento suorittaa osittaisen vastaavuuden. Esimerkiksi kun etsimme tekstiä me, mallin vastaavuus onnistui myös muissa teksteissä. Kuten web, verkkosivut ja olivat.
Tämän rajoituksen voittamiseksi voimme käyttää -w-vaihtoehtoa, joka pakottaa koko sanan vastaavuuden.
$ egrep -w we sample.txt

Toistaiseksi olemme käyttäneet egrep-komentoa niiden rivien tulostamiseen, joissa annettu kuvio esiintyy. Joskus kuitenkin halutaan suorittaa toimenpide päinvastoin.
Saatamme esimerkiksi haluta tulostaa rivit, joilla annettua kuviota ei ole. Voimme saavuttaa tämän -v-vaihtoehdon avulla:
$ egrep -v we sample.txt

Tässä näemme, että komento tulostaa kaikki rivit, jotka eivät sisällä tekstiä me.
Voimme käyttää komennon optiota -n ottaaksesi käyttöön rivinumeron, joka näyttää rivin numeron tulosteessa, kun kuvion sovitus onnistuu. Tämä yksinkertainen temppu tekee tuloksesta merkityksellisemmän.
$ egrep -n professionals sample.txt

Yllä olevassa tulosteessa voimme nähdä, että sana professionals on 5. rivillä.
Hiljaisessa tilassa egrep-komento ei tulosta vastaavaa kuviota. Joten meidän on käytettävä komennon palautusarvoa tunnistaaksemme, onnistuiko mallisovitus vai ei.
Voimme käyttää komennon optiota -q ottaaksesi käyttöön hiljaisen tilan, mikä on kätevää komentosarjoja kirjoitettaessa.
$ egrep -q professionals sample.txt $ egrep -q non-existing-pattern sample.txt

Tässä esimerkissä nollan palautusarvo ilmaisee kuvion olemassaolon, kun taas nollasta poikkeava arvo osoittaa kuvion puuttumisen.
Joskus on järkevää näyttää muutama rivi vastaavan kuvion ympärillä. Tällaisissa skenaarioissa voimme käyttää komennon -B-vaihtoehtoa, joka näyttää N riviä ennen sovitettua kuviota.
Esimerkiksi alla oleva komento tulostaa rivin, jolle mallin sovitus onnistuu, sekä 2 riviä ennen sitä.
$ egrep -B 2 -n professionals sample.txt

Tässä esimerkissä olemme käyttäneet vaihtoehtoa -n rivinumeroiden näyttämiseen.
Samalla tavalla voimme käyttää komennon vaihtoehtoa -A näyttääksesi rivit kuvion vastaavuuden jälkeen. Esimerkiksi alla oleva komento tulostaa rivin, jolla mallin täsmäytys onnistuu, sekä seuraavat 2 riviä.
$ egrep -A 2 -n professionals sample.txt
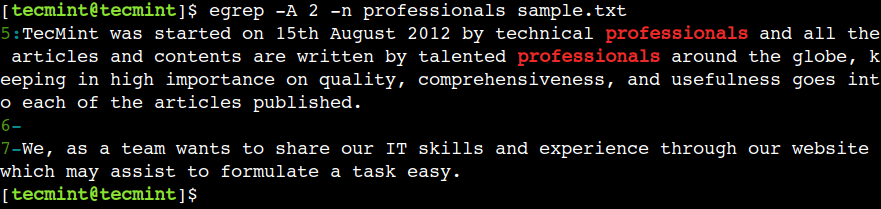
Tämän lisäksi egrep-komento tukee vaihtoehtoa -C, joka yhdistää vaihtoehtojen -A ja -B toiminnot, joka näyttää rivit ennen ja jälkeen sovitetun kuvion.
$ egrep -C 2 -n professionals sample.txt
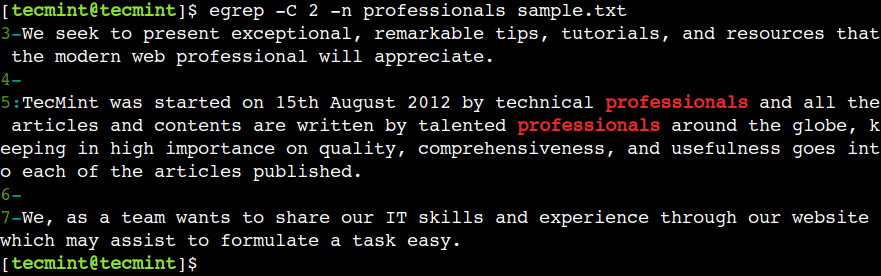
Kuten aiemmin keskusteltiin, voimme suorittaa kuvioiden sovituksen useille tiedostoille. Tilanne muuttuu kuitenkin hankalaksi, kun tiedostot ovat useissa alihakemistoissa ja välitämme ne kaikki komentoargumentteina.
Tällaisissa tapauksissa voimme suorittaa kuvioiden sovituksen rekursiivisesti käyttämällä -r-vaihtoehtoa seuraavan esimerkin mukaisesti.
Luo ensin 2 alihakemistoa ja kopioi niihin sample.txt-tiedosto:
$ mkdir -p dir1/dir2 $ cp sample.txt dir1/ $ cp sample.txt dir1/dir2/
Suoritetaan nyt hakutoiminto rekursiivisella tavalla:
$ egrep -r professionals dir1

Yllä olevassa esimerkissä voimme nähdä, että mallin täsmäytys onnistui dir1/dir2/sample.txt- ja dir1/sample.txt-tiedostoille.
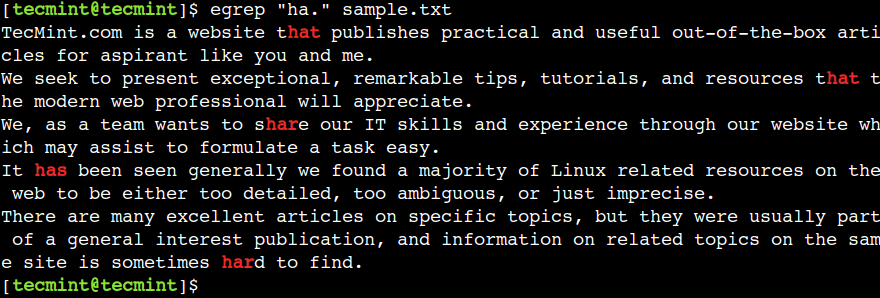
Voimme käyttää pistemerkkiä (.) vastaamaan mitä tahansa yksittäistä merkkiä paitsi rivin loppua. Esimerkiksi alla oleva säännöllinen lauseke vastaa tekstiä har, hat ja sisältää:
$ egrep "ha." sample.txt
Voimme käyttää tähteä (*) löytääksesi edellisen merkin nollan tai useamman esiintymän. Esimerkiksi alla oleva säännöllinen lauseke vastaa tekstiä, joka sisältää merkkijonon we ja sen jälkeen nolla tai useampia esiintymiä b.
$ egrep "web*" sample.txt

Voimme käyttää plusmerkkiä (+) vastaamaan yhtä tai useampaa edellisen merkin esiintymää. Esimerkiksi alla oleva säännöllinen lauseke vastaa tekstiä, joka sisältää merkkijonon we, jota seuraa vähintään yksi merkki b.
$ egrep "web+" sample.txt

Tässä voimme nähdä, että kaavavastaavuus ei onnistu sanoilla - me ja olimme, koska merkkiä b ei ole.
Voimme käyttää merkkiä (^) edustamaan rivin alkua. Esimerkiksi alla oleva säännöllinen lauseke tulostaa rivit, jotka alkavat tekstillä We:
$ egrep "^We" sample.txt

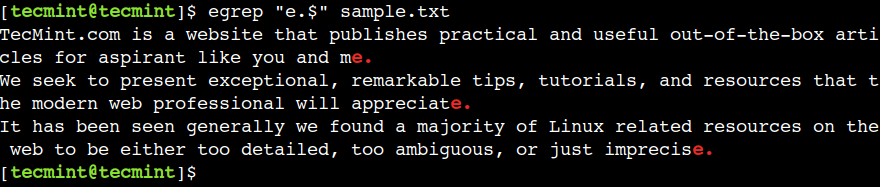
Voimme käyttää dollaria ($) edustamaan rivin loppua. Esimerkiksi alla oleva säännöllinen lauseke tulostaa rivit, jotka päättyvät tekstiin e.:
$ egrep "e.$" sample.txt
Voimme käyttää merkintä (^), jota seuraa välittömästi dollari ($) edustamaan tyhjää riviä. Käytä tätä säännöllisessä lausekkeessa tyhjien rivien poistamiseen:
$ egrep -n -v "^$" sample.txt
Yllä olevassa tulosteessa voimme nähdä, että rivinumerot 2, 4, 6, 8 ja 10 eivät näy, koska ne ovat tyhjiä.
Tässä artikkelissa käsittelimme hyödyllisiä esimerkkejä egrep-komennoista. Näitä esimerkkejä voidaan käyttää jokapäiväisessä elämässä tuottavuuden parantamiseen.
Tiedätkö muita parhaita esimerkkejä egrep-komennosta Linuxissa? Kerro meille mielipiteesi alla olevissa kommenteissa.